

🔸 1.58-Bit Quantization: Bringing Diffusion to Devices
Slimming Down AI Models for the Edge Device Revolution Using -1, 0, and 1's

Welcome back to Neural Notebook! Today, we're diving into a fascinating new development in AI model efficiency: 1.58-bit quantization. This cutting-edge technique is set to transform how we deploy AI models, especially in resource-constrained environments for both storage and inference.
If you're enjoying our content, consider subscribing to stay updated on the latest in AI and machine learning.
🧬 What is 1.58-Bit Quantization?
Modern AI models like DALLE and Midjourney are massive - they take a lot of power to run inference on and take up a ton of storage space. The end result - expensive per-token generation costs for end users.
That's why the magic of 1.58-bit quantization is paramount. This technique reduces the precision of model weights to just three values: -1, 0, and +1, using a ternary system instead of the traditional binary one. The result? A significant reduction in model storage and memory usage, making it ideal for edge devices (i.e. mobile).
But how does it work? By restricting the weights to these three values, the model can be efficiently packed, allowing one byte to express approximately five trits (ternary digits). This clever trick not only saves space but also speeds up processing, as the model can run faster with less data to crunch.
![[Uncaptioned image]](https://substackcdn.com/image/fetch/$s_!KFkU!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F62411696-f834-4b09-ba52-8c2c2468068c_1903x1526.png "[Uncaptioned image]")
⚡️ Why Does It Matter?
Large-scale text-to-image models like FLUX and DALLE are powerful but come with hefty computational costs, making them impractical for devices with limited resources. Enter 1.58-bit quantization, which slashes model storage by 7.7 times and inference memory usage by 5.1 times, all while maintaining comparable performance to full-precision models (source).
This means AI models can now run efficiently on battery-powered devices, reducing energy consumption and extending battery life. It's a game-changer for deploying AI on mobile and edge devices, where every bit of efficiency counts.
![[Uncaptioned image]](https://substackcdn.com/image/fetch/$s_!QWXg!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F5d8ccd0b-d672-4f1e-83c3-222b6379a01b_1617x612.png "[Uncaptioned image]")
⚙️ Technical Details Behind It
The secret sauce of 1.58-bit quantization lies in its post-training quantization approach. Unlike methods that require retraining models from scratch, this technique quantizes pre-trained models, making it more accessible and cost-effective. It operates solely on self-supervision, eliminating the need for additional image data during the quantization process.
Moreover, custom kernels optimized for 1.58-bit operations enhance inference efficiency, improving latency and making the model more practical for real-world applications. It's like giving your AI model a turbo boost without the extra fuel.
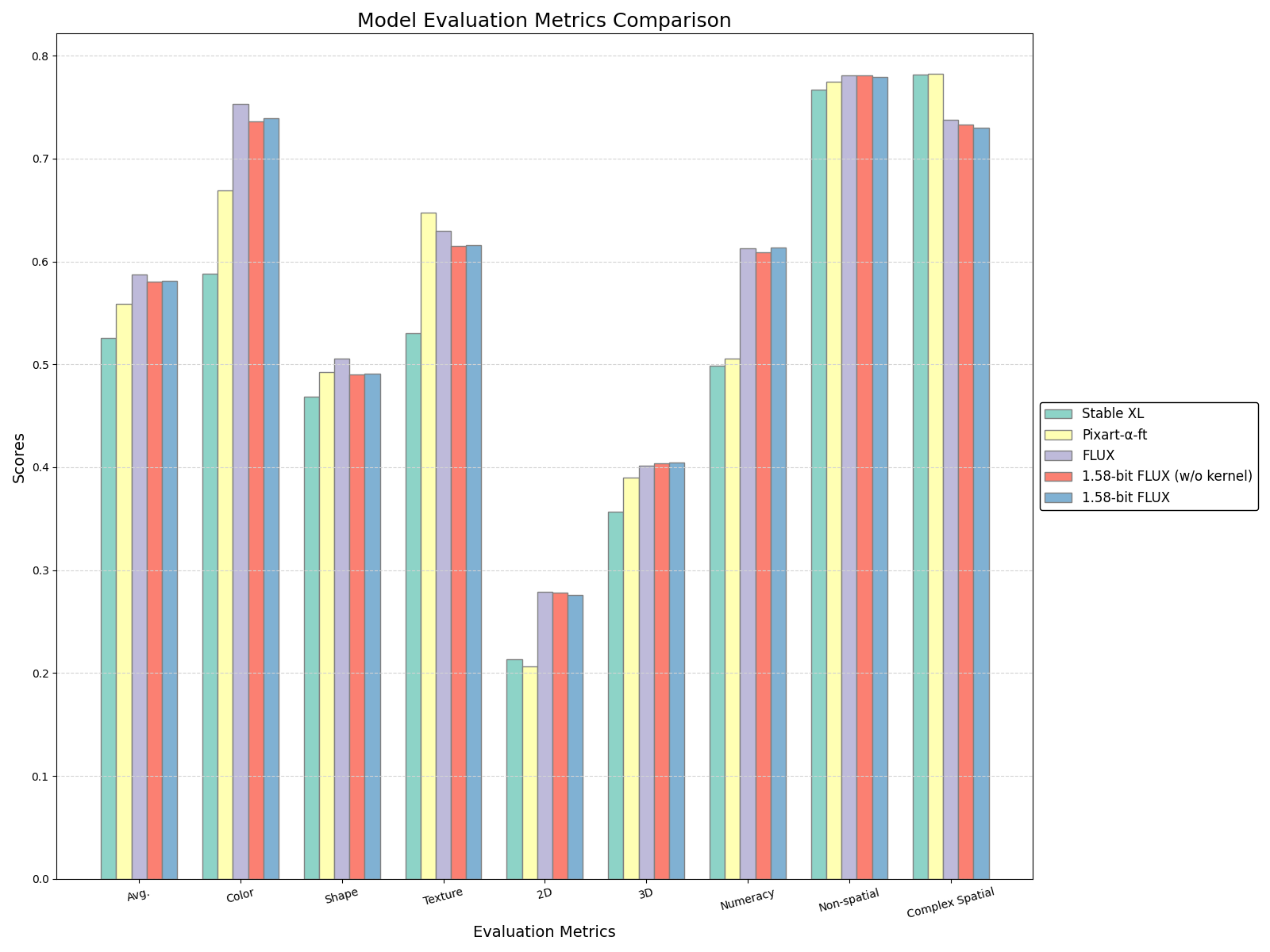
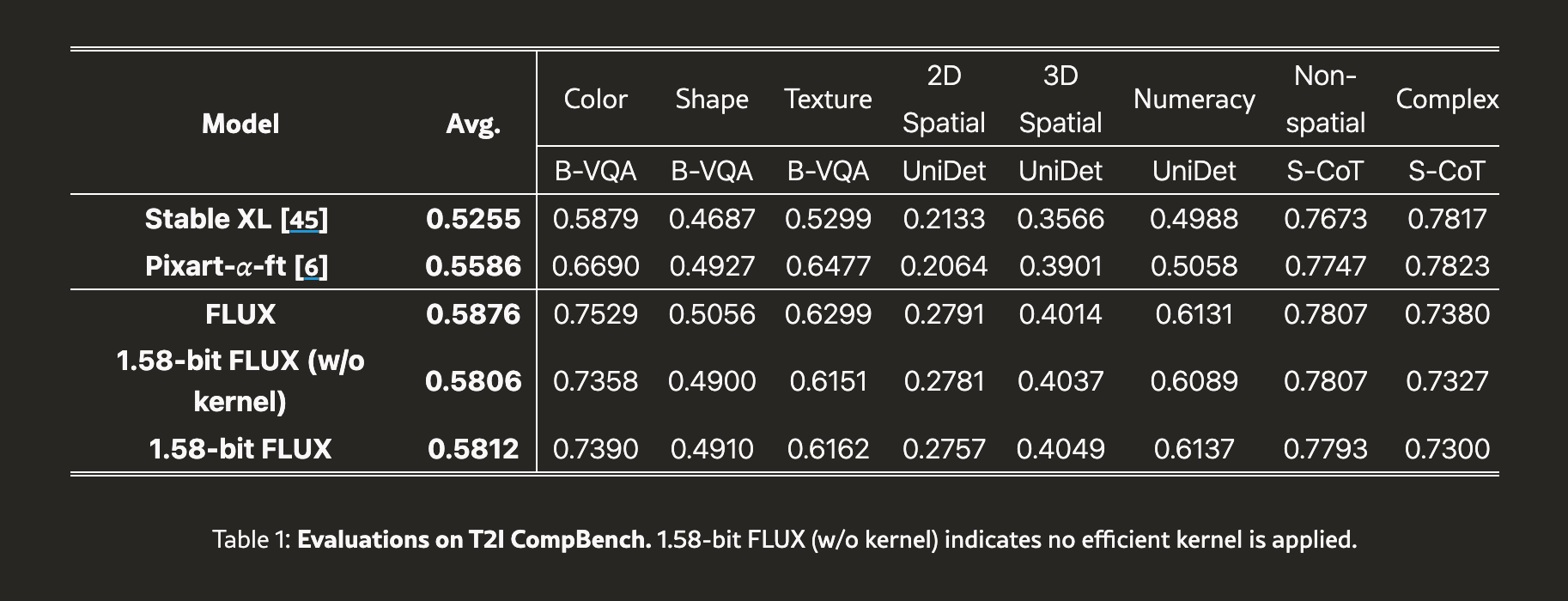
🌎 Real-World Applications
One exciting application for 1.58-bit quantization is in edge devices, where rapid, on-device text-to-image generation can be achieved without relying on cloud services. This opens up possibilities for real-time applications in areas like augmented reality, gaming, and personalized content creation.
Additionally, the reduced power requirements make it ideal for mobile devices, enabling high-quality image generation from text prompts on the go. Imagine creating stunning visuals with just a few taps on your smartphone, all powered by this lean and mean quantization technique.
🙊 Challenges and Solutions
One of the primary hurdles of implementing 1.58-bit quantization is the potential loss of model accuracy due to reduced precision. However, techniques like Quantization Aware Training (QAT) can mitigate this by training models with quantized weights from the start.
Another challenge is the lack of activation quantization in some models, which can limit speed improvements. Developing custom kernels optimized for 1.58-bit computation and incorporating activation quantization can enhance inference efficiency and reduce latency.
![[Uncaptioned image]](https://substackcdn.com/image/fetch/$s_!vk8d!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F393890c9-df1b-44c8-b457-c13c4ad69d2a_1846x1989.png "[Uncaptioned image]")
🤙 Others in the Scene
While 1.58-bit quantization is making waves, it's not the only player in the field. Other techniques like MixDQ and GPTQ offer their own strengths and applications. MixDQ excels in reducing model size and memory cost for few-step diffusion models, while GPTQ provides flexibility in quantization levels and is optimized for GPU inference.
Each method has its unique advantages, but 1.58-bit quantization stands out for its ability to drastically reduce model storage and inference memory usage without compromising performance. It's a testament to the power of innovation in the AI landscape.
🔬 Read the Research
This exciting advancement is detailed in the paper "1.58-bit Quantization: Revolutionizing Model Efficiency" by Chenglin Yang, Celong Liu, Xueqing Deng, Dongwon Kim, Xing Mei, Xiaohui Shen, and Liang-Chieh Chen. The authors, from ByteDance and POSTECH, present a groundbreaking approach to AI model compression, focusing on efficiency and practicality without compromising performance.
Learn more by reading the full paper here. For more details on the authors and their work, visit this link.
🔮 Future
The potential for 1.58-bit quantization is vast. With further optimizations in kernel implementations and activation quantization, we could see even greater improvements in latency and efficiency. This could pave the way for more robust models tailored for mobile devices, bringing high-quality AI capabilities to the palm of your hand.
Moreover, as more organizations adopt this technique, we can expect a surge in AI applications across industries, from healthcare to entertainment. The possibilities are endless, and the future is bright for this innovative approach to AI model efficiency.
1.58-bit quantization is a groundbreaking technique that's set to revolutionize how we deploy AI models, particularly in resource-constrained environments. By making models leaner and more efficient, it opens up new possibilities for AI applications across a range of devices and industries.
As we continue to explore the potential of this technology, one thing is clear: the future of AI is not just about making models smarter, but also making them more accessible and efficient. So, whether you're an AI enthusiast, developer, or investor, now is the time to pay attention to the exciting developments in 1.58-bit quantization.
Until next time,
The Neural Notebook Team
Website | Twitter
P.S. Don't forget to subscribe for more updates on the latest advancements in AI and how you can leverage them in your own projects.