

🔸 Multimodal AI: GPT with Eyes & Ears
From Virtual Assistants to Medical Breakthroughs, Multimodal AI is Reshaping the Landscape

Welcome back to Neural Notebook!
In today's edition, we're diving into a topic that's been making waves in the AI community: multimodal AI - combining different types of data (text, images, and audio) to create more powerful and versatile AI systems. And let me tell you, the implications are huge.
Before we jump in, here's a quick recap of what we've been covering lately:
If you're enjoying our posts, subscribe today to get the latest updates on AI, technology, and the future of product development, delivered straight to your inbox!
Now, let's dive into the world of multimodal AI and explore why it's such a game-changer.
Why Should You Care About Multimodal AI?
AI has already been creating shockwaves in various industries and, by combining different data types, multimodal AI opens up a whole new world of possibilities for AI applications.
Imagine a virtual assistant that can not only understand your voice commands but also analyze the images you send it. Or a medical AI system that can process a patient's medical records, X-rays, and CT scans to provide a more accurate diagnosis. These are just a few examples of what multimodal AI can do.
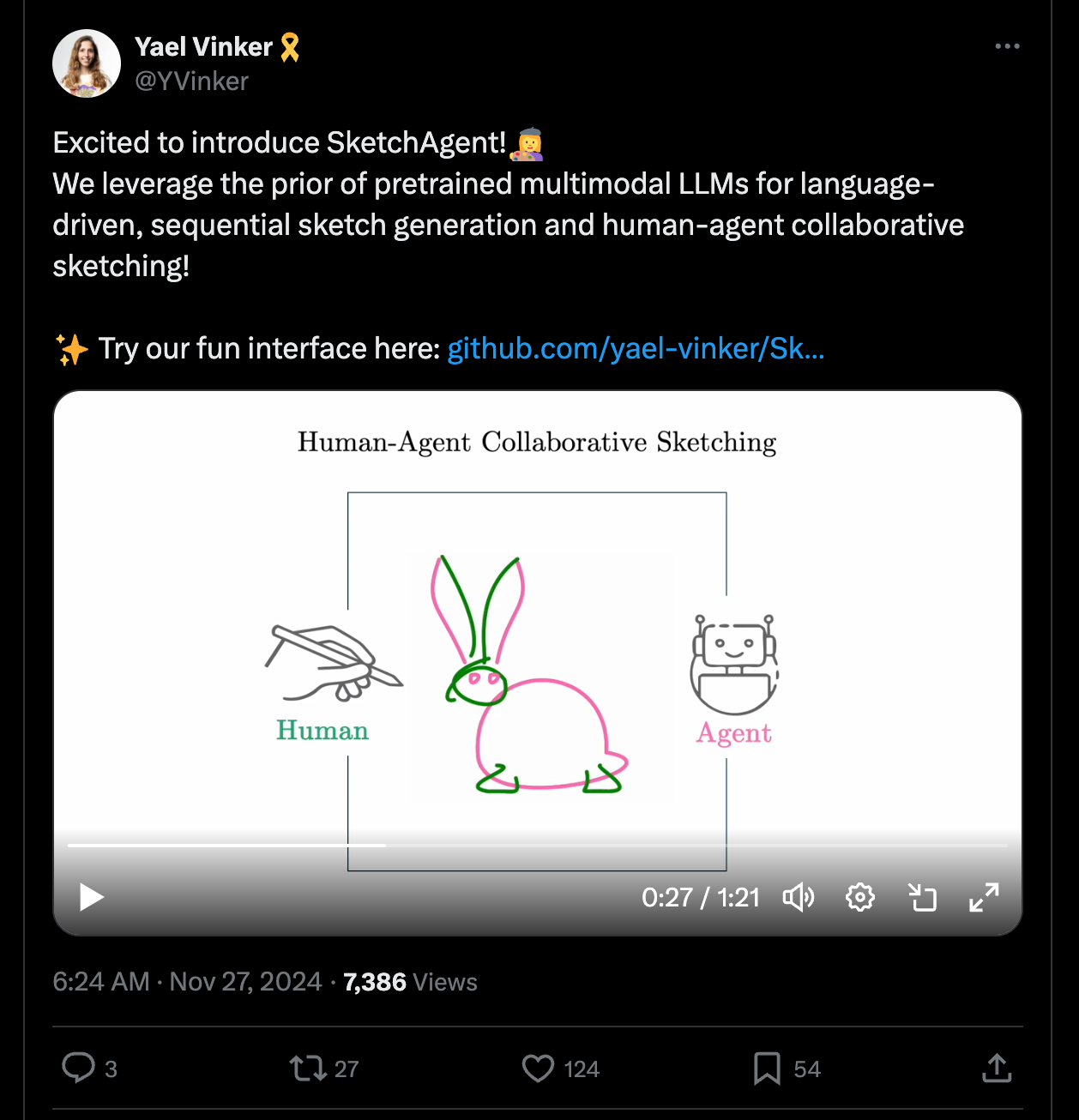
Check out this insane demo by Yael where they’re co-creating an art piece with a multi-modal AI assistant:
The Power of Data Integration
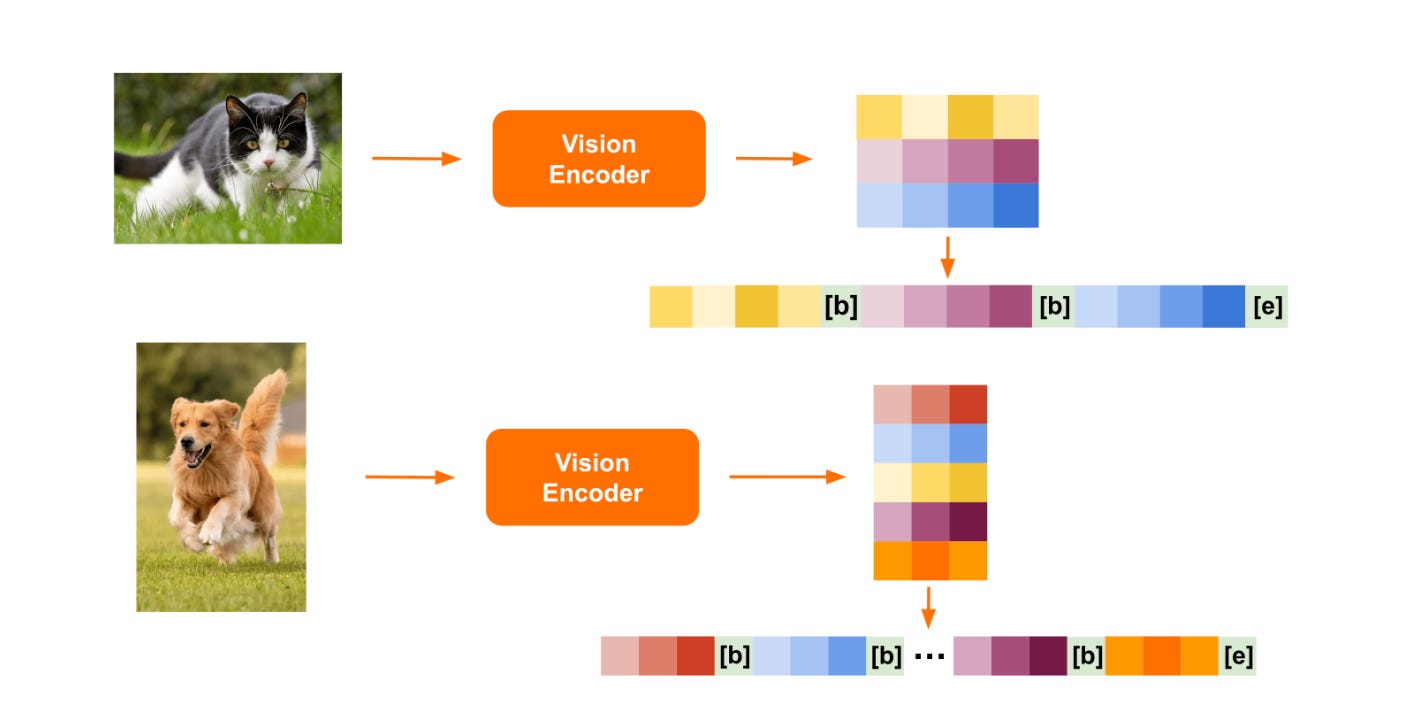
One of the key aspects of multimodal AI is its ability to integrate diverse data types. Traditional AI systems usually focus on a single modality, like natural language processing (NLP) for text or computer vision for images. But in the real world, data rarely comes in just one form.
Multimodal AI combines text, images, audio, video, and other data types to create a more holistic understanding of the world. By leveraging multiple modalities, AI systems can capture context and nuance that might be missed by unimodal systems.
Think of it like this: when you're having a conversation with someone, you don't just listen to their words. You also pick up on their tone of voice, facial expressions, and body language. All of these cues help you understand the full meaning of what they're saying. Multimodal AI works in a similar way, using multiple data sources to gain a more comprehensive understanding of the task at hand.
Enhanced Understanding and Efficiency
So, what are the benefits of this data integration? For one, it leads to more accurate and contextually informed outputs. By processing multiple modalities, multimodal AI can pick up on subtle cues and connections that unimodal systems might miss.
Another advantage is improved efficiency. Multimodal models often require less data for training, as they can leverage diverse data sources to improve performance. This is especially important in domains where labeled data is scarce, like healthcare or scientific research.
Multimodal AI also has the potential to uncover cross-modal insights—relationships between different data types that might not be apparent at first glance. For example, a multimodal AI system might discover a connection between a patient's medical images and their genomic data, leading to new insights into disease mechanisms and potential treatments.

The Building Blocks of Multimodal AI
Now that we've covered the benefits, let's take a closer look at the components that make up a multimodal AI system:
Input Module: This is where the magic begins. The input module gathers and preprocesses data from multiple sources, like text documents, images, audio files, and sensor data.
Fusion Module: Once the data is collected, it needs to be integrated. The fusion module is responsible for combining the various data types in a way that allows for comprehensive analysis. This is where techniques like early fusion (combining raw data) and late fusion (combining processed features) come into play.
Processing Algorithms: With the data fused, it's time for the heavy lifting. Multimodal AI employs various algorithms and models to analyze the combined data and generate insights or outputs. This might involve deep learning architectures like transformers or graph neural networks, depending on the task at hand.

A Step Towards AGI?
One of the most exciting aspects of multimodal AI is its potential to bring us closer to artificial general intelligence (AGI). AGI refers to the hypothetical ability of an AI system to understand and learn any intellectual task that a human can. In other words, it's the kind of AI you see in sci-fi movies—a machine that can think, reason, and adapt like a human.
While we're still a long way from achieving AGI, multimodal AI is seen as a significant step in that direction. By processing and understanding diverse forms of information simultaneously, multimodal AI systems are starting to mimic human-like perception and cognition.
Recent Advancements and Implications
So, what's new in the world of multimodal AI? Let's take a look at some recent advancements and their implications:
Pixtral: Developed by researchers at Salesforce, Pixtral is a high-performance multimodal model for image and text processing. What sets Pixtral apart is that it's trained with interleaved image and text data, making it natively multimodal from the ground up.
GitHub Copilot Upgrade: GitHub recently announced an upgrade to its AI-powered coding assistant, Copilot. The new multi-modal upgrade expands Copilot's ability to handle various types of input, from code snippets to natural language descriptions and even images. This could revolutionize the way developers interact with AI tools.
Multi Modality RAG: Researchers have proposed a new approach to Retrieval-Augmented Generation (RAG) using multiple modalities. RAG is a technique that allows AI models to retrieve relevant information from external sources to generate more informed outputs. By incorporating multiple modalities, this approach could transform AI's ability to generate contextually enriched content.
These advancements have far-reaching implications across industries. In healthcare, multimodal AI is already being used to analyze medical images, patient records, and genomic data for more accurate diagnoses and personalized treatments. In human-computer interaction, multimodal AI is enabling more intuitive and natural interactions by combining text, voice, gestures, and other modalities.
Looking to the Future
As we look to the future, it's clear that multimodal AI will play an increasingly important role in shaping the AI landscape. By 2034, experts predict that multimodal AI will be thoroughly tested and refined, offering more human-like communication capabilities in AI systems.
But the future of multimodal AI isn't just about making AI more human-like. It's about unlocking new possibilities and insights that were previously out of reach. As multimodal AI continues to evolve, we can expect to see breakthroughs in fields like medicine, education, and creative industries.
For AI product builders and investors, this presents a wealth of opportunities. From developing more engaging virtual assistants to creating AI tools that can generate rich, multimodal content, the possibilities are endless. The key is to stay ahead of the curve and invest in the right technologies and talent.
Multimodal AI is more than just a buzzword—it's a fundamental shift in how we approach AI development. By combining multiple data types and modalities, multimodal AI is opening up new frontiers in AI research and application.
As we've seen, multimodal AI has the potential to revolutionize industries, improve efficiency, and bring us closer to AGI. But more than that, it has the potential to change the way we interact with and understand the world around us.
So whether you're an engineer, tech enthusiast, or AI product builder, now is the time to start exploring the possibilities of multimodal AI. The future is multimodal, and it's up to us to shape it.
Until next time,
The Neural Notebook Team
P.S. Don't forget to subscribe for more updates on the latest advancements in AI, and how you can start leveraging them in your own projects.